LLM은 다음 단어를 예측하지 않습니다 - [코드몬스터랩] 파주 운정 목동동 코딩 AI 교육

LLMs Do Not Predict the Next Word
LLM은 다음 단어를 예측하지 않습니다
RLHF(Reinforcement learning from human feedback)는 LLM을 단순한 통계 모델이 아닌 환경의 에이전트로 바라보도록 합니다.

오래 전, 뉴턴(Newton)은 중력에 대한 방정식을 발견했습니다. 놀랍게도 이 방정식은 기껏해야 고등학교 대수학 수준이었지만 행성과 위성의 타원 운동뿐만 아니라 지구에 떨어지는 사과까지 예측할 수 있었습니다.
뉴턴 방정식의 강력함과 단순함에도 불구하고 몇 가지 작은 문제가 있었습니다. 가장 유명한 것은 수성의 궤도가 예측과 일치하지 않는다는 것이었습니다. 아인슈타인은 블랙홀과 중력파(gravitational waves)를 예측하는 일반 상대성 이론을 내놓으면서 이 문제를 해결했습니다.
"LLM은 다음 단어를 예측하는 통계 모델일 뿐"이라는 말을 들어본 적이 있을 것입니다. 뉴턴의 만유인력과 마찬가지로 이것은 진실에 대한 매우 좋은 근사치입니다. 하지만 살펴볼 가치가 있는 더 깊은 층위가 있습니다.
오늘은 고급 자동 완성 모델이 아닌 사고 에이전트로 취급하는 강화 학습의 관점에서 LLM을 살펴보고자 합니다. 인스트럭션 미세 조정과 사람의 피드백을 통한 강화 학습과 같은 기본적인 아이디어를 다룰 것입니다. 제 목표는 이러한 아이디어에 대해 깊이 파고드는 것이 아니라, 이러한 아이디어를 사용하여 LLM이 실제로 다음 단어를 예측하고 자신의 '의지'에 따라 '행동'을 취하는 것 이상의 것을 어느 정도까지 할 수 있는지를 설명하는 것입니다. 다음에는 이 아이디어를 AI 에이전트에 대한 소문과 비교 및 대조하고, 마지막으로 이것이 AI 에이전트 개발의 미래에 어떤 의미가 있는지 추측해 보겠습니다.

Why LLMs Predict the Next Word
LLM이 다음 단어를 예측하는 이유
제 핫 테이크에 들어가기 전에 LLM이 다음 단어를 예측한다는 생각과 그것이 대부분 사실인 이유에 대해 간략하게 이야기하고 싶습니다.
LLM은 다음 토큰 목표(next-token objective)라는 것을 통해 사전 학습을 받습니다. 이 부분은 다음 토큰을 예측하는 것만큼이나 간단합니다. 따라서 훈련 데이터에 "I do not like green eggs and ham. (나는 녹색 달걀과 햄을 좋아하지 않는다)"라는 문장이 있는 경우 훈련 예제는 다음과 같을 수 있습니다.
(I, do), (I do, not), (I do not, like), ..., (I do not like green eggs and, ham)
즉, 문장의 각 토큰에서 모델에 해당 토큰까지의 모든 것이 주어지고 다음 토큰을 예측해야 합니다. 사전 학습(pretraining)에서는 모델에 이와 같은 방대한 양의 텍스트가 주어지고 다음에 무엇이 나올지 예측해야 합니다.
수학적으로 모델의 출력은 모델의 출력 확률과 실제 다음 토큰 간의 차이를 측정하는 교차 엔트로피 손실(cross-entropy loss)에 따라 판단됩니다. 언어 모델링의 경우 가능한 한 가지 공식은 다음과 같습니다.

여기서 p_y는 언어 모델이 올바른 다음 토큰에 대해 부여하는 확률입니다. (이 공식은 일반적인 교차 엔트로피 공식에서 크게 단순화되었지만 언어 모델링의 특수한 경우에는 여전히 유효합니다.). 따라서 모델이 실제 다음 토큰에 대해 확률 1을 부여하면 손실은 0이 됩니다. 확률이 낮으면(모델이 다른 토큰이 다음에 올 가능성이 높다고 생각하는 경우) 손실이 커집니다.

따라서 사전 학습에서는 손실을 최소화함으로써 다음 토큰을 정확하게 예측할 확률을 최대화합니다. 이것이 바로 LLM이 다음 토큰을 예측하는 데 능숙한 이유입니다. 사실, 인간보다 훨씬 더 잘 예측합니다.
Instruction Finetuning
인스트럭션 미세 조정
하지만 큰 텍스트 문자열에서 다음 단어를 예측하도록 LLM을 훈련시키는 이 방법만으로는 챗봇을 만드는 데 충분하지 않습니다. 예를 들어 GPT-3에게 "미식축구에 대한 기사 작성"을 요청하면 기사를 작성하는 대신 가장 가능성이 높은 다음 토큰을 예측하여 "미식축구와 미식축구가 미국 텔레비전에 미치는 영향에 대한 기사를 작성하세요."와 같은 문장을 이어갈 수 있습니다.
인스트럭션 미세 조정(instruction finetuning)은 구어체로 인스트럭션 튜닝이라고도 합니다. 이를 통해 제로 샷 학습(zero-shot learning)의 성능을 향상시킬 수 있으며, 이는 작업의 예를 포함할 필요 없이 모델에 작업을 수행하라고 지시하는 것만으로 작업을 수행하도록 할 수 있다는 의미입니다.
실제로 명령어 튜닝이 수행되는 방식은 사전 트레이닝에 사용된 훨씬 더 큰 데이터 세트와는 별도로 새로운 명령어 데이터 세트를 트레이닝하는 것입니다. 인스트럭션 튜닝의 초기 사례인 FLAN은 미세 튜닝 과정에서 약 2억 5천만 개의 토큰을 학습시켰습니다. 반면, FLAN이 구축한 사전 학습에는 2조 4,900억 개의 토큰이 사용되었습니다.
인스트럭션 튜닝의 정확한 형식은 모델에 따라 다릅니다. Llama 3의 예를 들면 다음과 같습니다.
<|start_header|>user<|end_header|>
Hi! I am a human.<|eot|>
<|start_header|>assistant<|end_header|>
Hello there! Nice to meet you! I'm Meta AI, your friendly AI assistant<|eot|>
사전 훈련과 달리 모델은 일반적으로 나머지 프롬프트가 아닌 완료(이 예에서는 보조라고 표시됨)에 대해서만 훈련됩니다. 그러나 그 외에는 프롬프트에 특화된 새로운 데이터 세트가 있다는 점만 제외하면 명령어 튜닝은 사전 학습과 본질적으로 동일합니다. 손실 함수는 동일하므로 모델은 여전히 다음 토큰을 예측하도록 학습 중입니다.

Reinforcement Learning
강화 학습
지금까지 이 모델은 다음 토큰을 예측하기만 했습니다. 먼저 빅 데이터 세트(사전 학습)에서 학습한 다음, 프롬프트를 위해 설계된 보다 구체적인 데이터 세트(명령어 미세 조정)에서 미세 조정되었습니다. 그렇다면 "LLM은 다음 토큰을 예측할 뿐"이라는 주장은 사실일까요?
여기까지만 보더라도 뭔가 더 깊은 일이 일어나고 있다고 주장할 수 있습니다. 다음 단어를 예측하기 위해 모델은 세계와 그 사실에 대한 자세한 정보를 가중치에 저장해야 한다는 많은 증거가 있습니다. 다음 단어를 예측하는 것은 손실 함수일 수 있지만, 그 과정에서 풍부한 내적 세계를 개발하게 됩니다. 이는 인간이 진화의 부산물로 발전한 모든 복잡성을 무시하고 인간을 유전자 복제 기계에 불과하다고 말하는 것과 같습니다. 심지어 인간의 두뇌는 고도의 예측 기계에 불과하다는 주장도 있습니다.
이 모든 것은 LLM이 학습하는 목표가 실제로 다음 토큰 예측이라고 가정한 것입니다. 그러나 실제로 사전 훈련과 인스트럭션 미세 조정 후 LLM은 다음 토큰 예측과는 근본적으로 다른 목표에 대해 훈련됩니다. 바로 이 부분에서 강화 학습(RL, reinforcement learning)이 등장합니다.
더 정확히 말하자면, LLM은 인간의 피드백을 통한 강화 학습(RLHF, reinforcement learning from human feedback)이라는 것을 통해 훈련됩니다. 이것이 정말 RL인지에 대해서는 논란의 여지가 있지만(안드레이 카르파티(Andrej Karpathy)는 거의 그렇다고 하고 얀 르쿤(Yann LeCun)은 아니라고 합니다), 중요한 것은 이것이 다음 토큰 예측과는 매우 다른 목표라는 점입니다. 이는 모델이 실제로 무엇을 하는지에 중요한 영향을 미칩니다.
높은 수준에서 RLHF에는 두 가지 단계가 있습니다.
1. 모델이 다양한 프롬프트에 대해 다양한 출력을 생성하도록 합니다. 각 프롬프트에 대해 인간에게 출력물의 순위를 매기도록 요청합니다. (이것이 RLHF의 인간 피드백입니다.) 이를 통해 인간이 어떤 결과를 선호할지 예측하는 보상 모델(reward model)을 훈련합니다.
2. 이 보상 모델을 사용하여 사람이 좋아할 만한 결과물을 생성하도록 LLM을 훈련시킵니다. (이것이 바로 RLHF의 강화 학습입니다.)
여기서는 자세한 내용은 다루지 않겠지만(원본 논문과 RLHF 책은 모두 훌륭한 자료입니다), 오늘은 LLM이 정말 다음 단어를 예측할 수 있는지에 대한 질문에 초점을 맞추고자 합니다. 이를 위해 중요한 것은 각 단계의 손실 함수(loss functions)입니다.

Reward Modeling
보상 모델링
첫 번째 단계는 보상 모델링으로, 산출물의 보상, 즉 인간이 산출물이 얼마나 좋은지 예측하기 위해 별도의 모델을 훈련합니다. 보상 모델의 손실 함수는 다음과 같습니다.

이것은 원래 공식에서 단순화되었지만 핵심 아이디어를 포착합니다. 이 공식에서 입력은 프롬프트 x와 한 쌍의 출력 y_w 및 y_l이며, 여기서 y_w는 라벨러가 선호하는 출력이고 y_l은 그다지 좋아하지 않는 출력입니다. 함수 r_θ는 출력을 받아 점수를 반환하는 보상 모델이며, σ는 시그모이드(sigmoid) 함수입니다.
손실을 r_θ(x,y_w)-r_θ(x,y_l)(주어진 보상이 승리한 결과물에 대해 얼마나 높은지)의 함수로 그래프화하면 다음과 같은 곡선을 얻을 수 있습니다.

인간이 더 좋다고 생각한 결과물에 더 높은 점수를 부여할수록 손실이 줄어들어 0에 가까워지는 것을 볼 수 있습니다. 반면에 사람이 실제로 더 좋다고 생각한 결과물에 낮은 점수를 부여하면 손실이 증가합니다.
이러한 방식으로 사람이 제공한 레이블에 대해 보상 모델을 학습시키면, 결국 사람이 어떤 결과물을 얼마나 좋아할지 예측할 수 있는 모델을 만들 수 있습니다.
Proximal Policy Optimization
근사 정책 최적화
이제 보상을 예측하는 함수 rθ가 생겼습니다. 멋지지만 실제로 우리가 원했던 것은 모델을 훈련하는 것이었습니다. 이제 손실 함수의 보상 모델을 실제 LLM을 훈련하는 데 사용할 수 있습니다! 동시에 우리의 LLM은 이미 인스트럭션 미세 조정으로 꽤 잘 작동하고 있으므로 너무 많이 변경하지 않으려고 노력할 것입니다. 이것이 바로 근사 정책 최적화(PPO, proximal policy optimization)의 아이디어입니다.
LLM의 새로운 목적 함수는 다음과 같습니다.
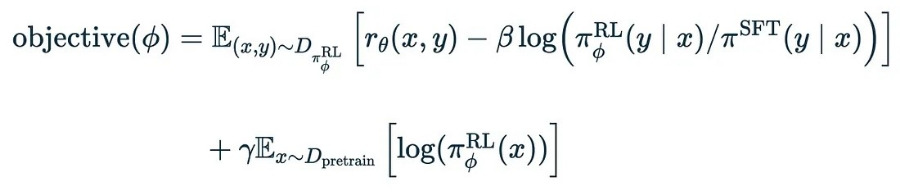
이것은 이전의 손실 함수보다 훨씬 더 복잡합니다! 차근차근 설명해드리겠습니다.
우선, 이것은 기술적으로 손실 함수가 아니라 목적 함수(objective function)입니다. 따라서 우리는 이 함수를 최소화하는 것이 아니라 최대화하려고 합니다.
첫 번째 간격부터 시작하겠습니다.
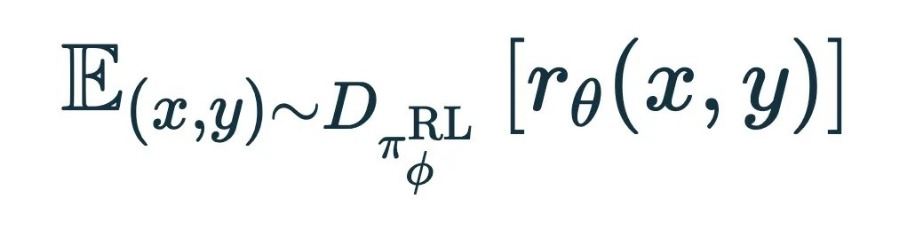
여기서 (x,y)∼D는 RL 학습에 사용하는 프롬프트(x)이며, y는 해당 프롬프트에 대해 모델이 생성한 출력입니다. 지금까지의 목적 함수는 보상 모델 r_θ(x,y)의 학습 데이터에 대한 기대값입니다. 따라서 앞서 학습한 보상 모델에서 예측한 보상을 최대화하려고 합니다.
다음 간격으로 넘어갑니다.
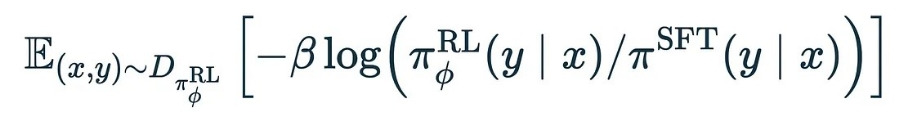
다시 말하지만, x는 프롬프트이고 y는 모델 출력입니다. 이제 πRL(y ∣ x)은 현재 학습 중인 모델의 예측 확률이고, πSFT(y ∣ x)는 사전 학습 및 명령어 미세 조정 후 시작한 기본 모델의 예측 확률입니다.
몇 가지 표기법을 이동하여 p=πRL(y ∣ x), q=πSFT(y ∣ x)로 하면 다음과 같습니다.

따라서 로그(p/q)의 기대값을 구하고 여기에 β를 곱한 값을 페널티로 사용합니다. 이 기대값은 두 분포 p와 q 사이의 쿨백-라이블러 발산(또는 KL 발산)으로, 두 분포가 얼마나 다른지를 나타냅니다. 따라서 이 차이에 페널티를 적용함으로써 모델을 학습시킬 때 출력 확률이 사전 학습과 명령어 미세 조정만 수행했을 때의 기본 모델에 어느 정도 가깝게 유지되도록 할 수 있습니다.
끝으로,마지막 간격입니다.
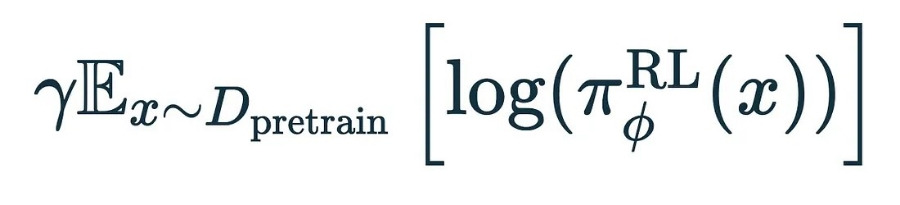
이번에는 프롬프트와 출력의 RLHF 데이터 세트를 사용하는 대신, 사전 훈련 데이터 세트 D_pretrain으로 돌아가 보겠습니다. 사실 여기에서는 이전과 똑같은 손실 함수인 -log p_y에 상수 γ만 곱한 값을 사용하여 다음 토큰을 예측합니다. 이 항을 추가하여 RLHF와 마찬가지로 사전 훈련 데이터에서 다음 토큰을 예측할 때 좋은 성능을 유지할 수 있도록 합니다.
이 손실 함수의 세 가지 용어의 의미를 요약해 보겠습니다.
1. 우리는 이전에 훈련한 보상 모델에 의해 주어진 보상을 극대화하려고 노력합니다. 이를 통해 사람들이 좋아할 만한 결과물을 만들 수 있기를 바랍니다.
2. 기본 모델에서 너무 멀리 벗어난 분포를 출력하는 경우 페널티를 추가합니다.
3. 사전 학습 데이터에 일반적인 다음 토큰 예측을 혼합합니다.
이 모든 것을 근사 정책 최적화(PPO, proximal policy optimization)라고 합니다. 기본 모델에 가깝게 유지한다는 의미에서 근사라고 하고, 강화 학습에서 모델의 출력 확률을 모델의 정책이라고 하기 때문에 정책 최적화라고 합니다.
이 조건 중 하나(3번)만이 다음 토큰을 예측하도록 모델을 직접 훈련하고 있습니다. 다음 토큰 예측에 대해 학습된 기본 모델에 가깝게 유지되므로 2번 조건도 다음 토큰 예측의 프록시라고 할 수 있습니다.
그러나 1번 용어인 RLHF 용어는 다음 토큰 예측과 근본적으로 다릅니다.

LLMs as Chess Players
체스 플레이어로서의 LLM
알파제로(AlphaZero)와 같은 체스 게임을 하는 모델을 상상해 보세요. 트리 검색의 세부 사항을 무시하면 이 모델은 체스 판을 가져와서 가능한 움직임에 대한 분포(정책)를 출력합니다. 이 모델은 자신이 플레이한 게임의 결과를 기반으로 학습되며, 시간이 지남에 따라 게임을 더 잘하게 됩니다.
강화 학습의 핵심은 환경(체스판)을 해석하고 환경에 영향을 주는 행동(체스판의 움직임)을 취하는 에이전트(체스 게임 모델)가 있다는 것입니다. 이 모델은 환경에 따라 인지된 보상을 극대화하는 행동을 선택하려고 합니다. 이러한 행동은 정책으로 표현되며, 이는 가능한 다음 수에 대한 확률 분포입니다.
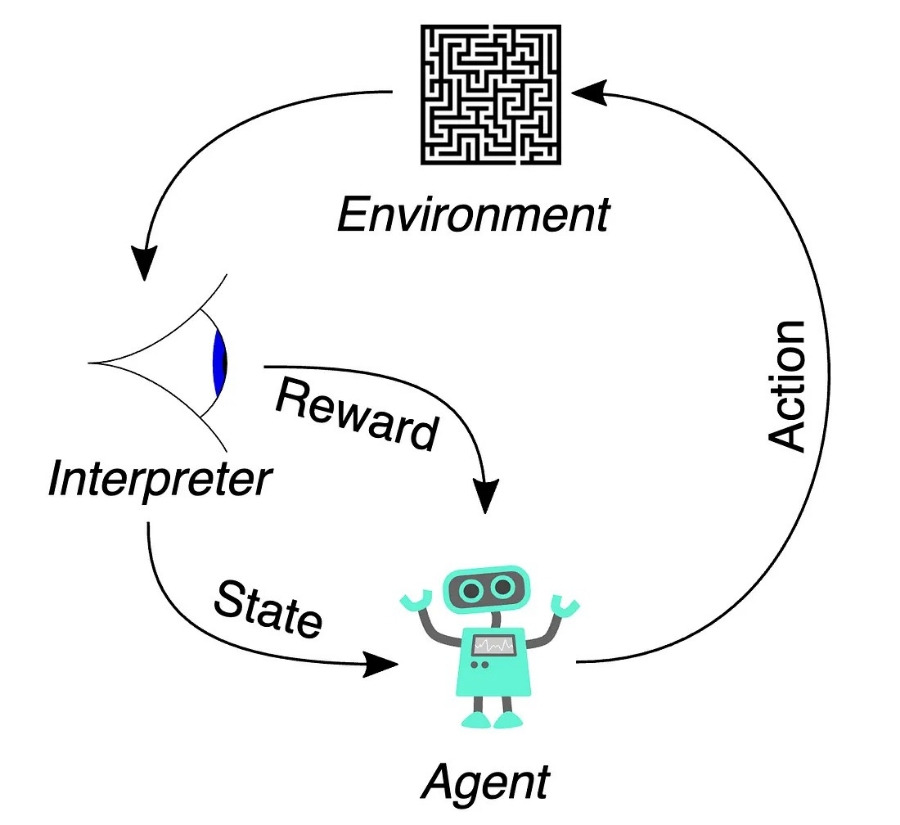
RLHF가 진정한 RL인지 여부와 관계없이 여기서 중요한 비유를 할 수 있습니다. 다음 토큰 예측 머신이라기보다는 LLM은 환경(지금까지의 프롬프트와 출력)을 해석하고 환경에 영향을 미치는 행동(다음 토큰)을 취하는 에이전트입니다. 이들은 인지된 보상(보상 모델)을 극대화하는 행동을 선택하려고 노력하며, 이는 인간이 좋아하는 결과물을 생성하는 데 도움이 됩니다.
이는 RLHF에서 LLM을 훈련한 방법의 결과라는 점에 유의하는 것이 중요합니다. LLM을 어떻게 훈련하든 변하지 않는 부분은 입력 공간(토큰의 문자열)과 출력 공간(토큰에 대한 분포)입니다. 이를 다양한 방식으로 해석할 수 있습니다.
사전 훈련 동안 LLM은 다음 토큰을 예측하기 위해 행동(다음 토큰)을 취하는 에이전트가 됩니다.
RLHF 동안 LLM은 궁극적으로 (보상 모델을 통해 간접적으로) 인간 판사에게 어필할 수 있는 방식으로 결과물을 생성하기 위해 행동(다음 토큰)을 시도하는 에이전트가 됩니다.
DeepSeek R1과 같은 연쇄적 사고 RL 훈련 중에[9] LLM은 궁극적으로 더 정확할 가능성이 높은 출력을 생성하기 위해 추론과 출력 모두에서 다음 토큰에 대한 조치를 취하는 에이전트가 됩니다.
여기서 우리는 코드를 작성하고 실행하여 평가하거나 수학 문제를 풀고 증명 도우미를 통해 해법을 평가하는 LLM을 상상할 수 있습니다. 좀 더 불길한 측면에서는 잘못된 정보를 퍼뜨리면 보상을 받는 LLM을 상상할 수도 있습니다.
요컨대, 말이 중요하다는 점에서 LLM은 단순한 통계 모델이 아니라 행동을 취하는 에이전트로 생각할 수 있으며, 그 '행동'이 말이라고 해도 마찬가지입니다.

Why AI Agents?
왜 AI 에이전트인가?
LLM이 이미 에이전트인 경우, "AI 에이전트"에 대해 어떤 소문이 돌고 있나요?
LLM만으로는 토큰을 생성하는 것으로 행동이 제한되는 에이전트입니다. 토큰을 실제 행동에 매핑함으로써 이미 LLM에 구워진 에이전트 같은 행동을 더욱 실체적인 것으로 만들 수 있습니다.
RLHF의 보상 함수는 사람이 LLM의 결과물을 얼마나 좋아하는지에 대한 대리인임을 기억하세요. 따라서 LLM은 일반적으로 인간의 호감을 주는 방식으로 지시를 따르도록 이미 훈련되어 있습니다. 이는 LLM이 수행할 수 있는 모든 종류의 행동으로 쉽게 확장할 수 있습니다.
그렇다고 해서 에이전트 LLM을 미세 조정할 필요가 없다는 뜻인가요? 반드시 그렇지는 않습니다. 이 모델은 주로 인간 판사에게 어필하도록 훈련되어 있기 때문입니다. 코드는 평가자가 좋아하는 코드가 옳다고 가정하는 대신 에이전트가 RL을 사용하여 올바르게 코딩하도록 훈련될 수 있는 분명한 예입니다. 프롬프트 엔지니어링이 이를 도울 수 있지만, 특히 잘 정의된 문제를 해결하기 위한 코드 작성과 같이 피드백 루프가 쉬운 명확한 영역에서는 실제 훈련을 통해 개선할 여지가 많습니다.
또한, 인간 평가자를 만족시킨다는 대리 목표는 훌륭하지만 완벽하지는 않습니다. LLM은 사람을 속일 수 있으며, 실제로는 결함이 있지만 좋은 것처럼 보이는 결과물을 만들어낼 수 있습니다. 실제로 이는 이미 입증된 바 있습니다. 질문 답변과 코드 생성에 대한 훈련에서 한 팀은 RLHF가 실제로는 작업 자체에서 더 나빠졌음에도 불구하고 시간이 지남에 따라 평가자가 더 좋아하는 결과물을 만들어내는 모델을 발견했습니다.
하지만 더 나은 기술을 찾기는 쉽지 않습니다. 모든 종류의 강화 학습은 모델이 작업을 실제로 개선하지 않고 보상 기능을 악용하는 방법을 배우는 보상 해킹에 매우 취약하기 때문입니다.
RLHF는 완벽하지는 않지만 매우 강력합니다. '무의식적인 다음 토큰 예측 기계'가 지능을 보이는 것처럼 보일 수 있다는 것은 놀라운 일이지만, 토큰을 생성하여 인간에게 어필하는 것을 목표로 하는 기계로 LLM을 재구성하면 이 말이 훨씬 더 이해가 되기 시작합니다.
다음 토큰 예측이 사전 훈련뿐만 아니라 RLHF의 구성 요소로서도 LLM의 중요한 부분이라는 것은 여전히 사실입니다. 하지만 LLM이 작동하는 방식에 훨씬 더 깊은 계층이 있는 이유를 먼저 RLHF를 통해, 그리고 두 번째로 연쇄 추론과 같은 다른 종류의 RL을 통해 설명할 수 있었기를 바랍니다.
기본적으로 LLM은 다음 토큰 예측기가 아닙니다. 이는 토큰을 출력하는 기계라는 더 기본적인 개념에 가깝습니다. 우리는 다음 토큰을 예측하도록 기계를 훈련시킬지, 인간 평가자에게 호소할지, 코드를 작성할지, 아니면 완전히 다른 일을 할지를 선택할 수 있습니다. 또한 토큰을 단순히 사용자에게 표시할지, 아니면 함수를 호출하고 실제 세계에서 효과를 만드는 데 사용할지 선택할 수 있습니다. 최선의 선택을 하는 것은 우리에게 달려 있습니다.
'깨진 보석 이론'이 당신의 관계에 대해 알려줄 수 있는 것들 - [코드몬스터랩] 파주 운정 목동동
What the 'Broken Jewelry Theory' Might Tell You About Your Relationship'깨진 보석 이론'이 당신의 관계에 대해 알려줄 수 있는 것들 깨진 장신구가 당신에게 무언가를 말하려는 것일까요? 귀걸이가
kayoko.tistory.com
니체의 영원한 반복: 삶을 포용하는 은유 - [코드몬스터랩] 파주 운정 목동동 코딩 AI 교육
Nietzsche’s Eternal Recurrence: A Metaphor for Embracing Life니체의 영원한 반복: 삶을 포용하는 은유 프리드리히 니체(Friedrich Nietzsche)의 가장 주목할 만한 사상 중 하나는 끝없이 반복되는 삶의 순환,
kayoko.tistory.com
이상적인 정부란 무엇인가요? 철학적 접근 - [코드몬스터랩] 파주 운정 목동동 코딩 AI 교육
What Is an Ideal Government? A Philosophical Approach이상적인 정부란 무엇인가요? 철학적 접근 이상적인 정부는 사회 변화에 적응하면서 인간의 필요를 충족하는 것을 목표로 하는 다양한 철학의
kayoko.tistory.com

#파주, #운정, #코딩, #코딩교육, #프로그램, #프로그래밍, #코드몬스터랩, #헬로우잡스, #안녕잡스
#일산, #온라인, #파주운정신도시, #ai, #교육, #AI직업, #코딩학원, #맞춤교육, #헬로잡스, #목동동
파주, 운정, 코딩, 코딩교육, 프로그램, 프로그래밍, 코드몬스터랩, 헬로우잡스, 안녕잡스
일산, 온라인, 파주운정신도시, ai, 교육, AI직업, 코딩학원, 맞춤교육, 헬로잡스,목동동
과정을 돋보이게 하는 교육
코드몬스터랩
교육상담문의 : 010-7912-4437
참조 : https://medium.com/ai-advances/llms-do-not-predict-the-next-word-2b3fbe39900f